�@
�N���X�^�̍\���́A�قƂ�ǁi���ׂāj���W�X�g���Ɋi�[����Ă��܂��B���̃��W�X�g�����͊e�m�[�h�̃��[�J���h���C�u�ɕۑ�����Ă��܂��B�t�F�[���I�[�o�[���ɃN�H�[�������\�[�X����擾���܂��B
���W�X�g���t�@�C���p�X �F %windir%\Cluster\Clusdb
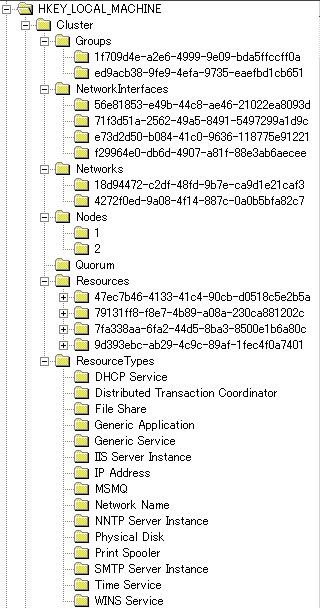 |
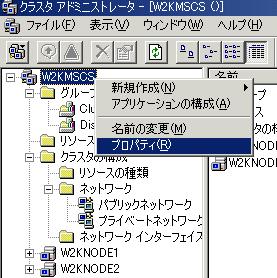
�N���X�^�̃��W�X�g���\���͉E�}�̂Ƃ���
HKLM\Cluster �ȉ��Ɋ܂܂�܂��B
�ȉ��̐����ł́A�e�G���g���̉E���ɂ́A�N���X�^�A�h�~�j�X�g���[�^�őΉ����Ă���ꏊ�������Ă��܂��B Groups - [�N���X�^��] - [�O���[�v] NetworkInterfaces - [�N���X�^��] -
[�N���X�^�̍\��] - [�l�b�g���[�N �C���^�[�t�F�[�X] Network - [�N���X�^��] -
[�N���X�^�̍\��] - [�l�b�g���[�N] Nodes - [�N���X�^��] -
<�m�[�h��> Resources - [�N���X�^��] -
[���\�[�X] ResourceType - [�N���X�^��] -
[�N���X�^�̍\��] - [���\�[�X�̎��] |
�@
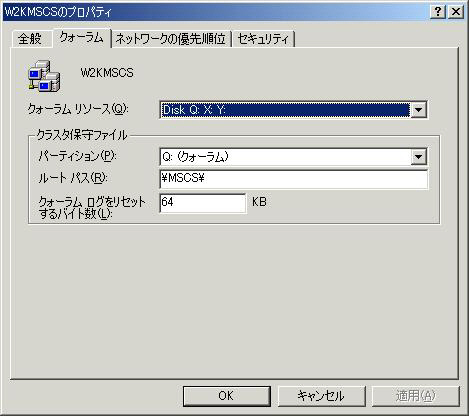
�N���X�^�ɂ̓N�H�[�������\�[�X�Ƃ����d�v�ȃ��\�[�X������܂��B�N�H�[�������\�[�X�ɂ͈ȉ��̏�i�[����܂��B
�N�H�[�������\�[�X�i�N�H�[�������\�[�X�̂���f�B�X�N�j�����L���Ă���m�[�h�݂̂��N���X�^�T�[�r�X��ł��܂��B
�N�H�[�������\�[�X�́A���̗p�������f�B�X�N�ɕۑ�����K�v������܂��B
�N�H�[�����p�̋��L�f�B�X�N�ɂ͉\�Ȍ���A���̃A�v���P�[�V���������Ȃ��悤�ɂ��܂��B�A�v���P�[�V�����̏�Q�ƈꏏ�ɃN�H�[�������t�F�[���I�[�o�[���Ă��܂��A�_�E���^�C���������Ȃ�����A�A�v���P�[�V��������Q���畜�A���Ȃ��ꍇ�ɂ́A�N���X�^�̊Ǘ����̂��ł��Ȃ��Ȃ�\��������܂��B
%QuorumDisk%\mscs\qoulog.log
�Е��̃N���X�^��ŕύX���ꂽ�\������ێ����Ă����܂��B�t�F�[���I�[�o�[���ɁA�ʃm�[�h��
quolog.log
�t�@�C������A�X�V������ǂݎ�胍�[�J�����W�X�g���ɔ��f�����܂��B
Clusdb = chk***.chk + quolog.log �ɂȂ��Ă���͂��B
%QuorumDisk%\mscs\chk***.tmp
chk***.tmp �� * �ɂ́A16
�i���Ŏ����ꂽ���l�i����ԍ��j������܂��B���̃t�@�C���́A���W�X�g���̃`�F�b�N�|�C���g�t�@�C���ŁA�ꎞ�O�̃��W�X�g������ێ����Ă��܂��Bregedt32.exe
�ɂāA[�n�C�u�̃��[�h]
���s���ƁA���g���Q�Ƃł��܂��B�N���X�^�\���̃��J�o���[�̎��Ȃǂɂ����ɗ����܂��B
HKLM\Cluster\RegistrySequence ���ŐV�̐���ԍ��ɂȂ�B
%QuorumDisk%\mscs\<GUID>\0000001.cpt
�t�@�C�����̐��l�̕����͐����ς��܂��B����́A�t�@�C���p�X�Ɏ����ꂽ
GUID �� [�ėp�A�v���P�[�V����] �y�� [�ėp�T�[�r�X]
���\�[�X�� [���W�X�g���̕���]
�Őݒ肳��Ă��郌�W�X�g������ێ����Ă��܂��B�t�F�[���I�[�o�[���ɁA���̃t�@�C������ʃm�[�h�̃��W�X�g���֔��f����܂��B���̃t�@�C�����Aregedt32.exe
�� [�n�C�u�̃��[�h] �ŊJ�����Ƃ��\�ł��B
Ownership
�N���X�^�m�[�h���N�������Ƃ��A�������̃m�[�h���N�H�[�������\�[�X�̏��L�҂ł�������AJoin�i����/�Q���j�����݂܂��B���L�҂����Ȃ��ꍇ�A���������L�҂ɂȂ�悤�ɃN�H�[�������\�[�X���擾���܂��B
| �v���p�e�B �N�H�[�������\�[�X�̊i�[�ꏊ�́A�N���X�^�̃v���p�e�B����ύX�ł��܂��B�N���X�^�̃v���p�e�B�ł́A�N�H�[�������O�̃f�t�H���g�T�C�Y�ύX��A�����ʐM�p�l�b�g���[�N�̗D��x��ύX�\�ł��B
|
 |
�@
�N���X�^�ł́A�p�u���b�N�l�b�g���[�N�iPublic Network�j�ƃv���C�x�[�g�l�b�g���[�N�iPrivate Network�j������܂��B�p�u���b�N�l�b�g���[�N�́A�N���C�A���g����A�N�Z�X�ɉ������܂��B�v���C�x�[�g�l�b�g���[�N�́A�N���X�^�m�[�h���m�̐�����̂����i�n�[�g�r�[�g�Ȃǁj���s����p�̃l�b�g���[�N�ł��B
�n�[�g�r�[�g�iHeartbeats�j
���m�[�h������ɓ��삵�Ă��邩���m�F����ʐM�ł��B��
1.2 �b�Ԋu��
�o�C�g�̃p�P�b�g�����܂��B�n�[�g�r�[�g�� 6 ��A���Ԃ��Ă��Ȃ��Ə�Q�ƔF�����܂��BUDP �|�[�g�� 3343�i0x0D0F�j ���g�p���܂��B�l�b�g���[�N��ɗ����p�P�b�g��
82 �o�C�g�ł��B�n�[�g�r�[�g�́A�ʃm�[�h���N�������A�i�E���X�����Ƃ�����A����̃m�[�h�ɑ��čs���܂��B�ʃm�[�h���N�����Ă��Ȃ��̂ɁA�n�[�g�r�[�g���o���Â���킯�ł͂���܂���B
NIC �̍\��
�N���X�^���\������ꍇ�A�P���Q�|�C���g�ia single point
of failure�j������邽�߂ɁANIC �� 2 ���ȏ�p�ӂ��܂��BNIC 1
���ł��\���ł��܂��������͂��܂���BNIC �� 1
���̏ꍇ�A���� NIC
���̏Ⴕ��������ʐM���ł��Ȃ��Ȃ邽�߂ł��BNIC �� 2
������ꍇ�́A�ꖇ���v���C�x�[�g�l�b�g���[�N��p�A�����ꖇ�͑S�Ă̒ʐM�Ɏg���i�v���C�x�[�g�ƃp�u���b�N�j�Ƃ����ݒ�ɂ��܂��B
NetBIOS �̕K�v��
�N���X�^�ł� NetBIOS ���K�{�ł��BWindows NT
�Ƃ̌݊���ۂ��߂ł��B�N���X�^�̓����ʐM�ɂ� NetBIOS
���g�p���܂��B�]���ăN���X�^���\������ NIC �ł́A�uNetBIOS
over TCP/IP
���ɂ���v�̐ݒ�ɂ͂��Ȃ��悤�ɂ��Ă��������B
NIC �̒lj�
�N���X�^�T�[�r�X�� Kerberos �͎g�p���܂���BNTLM
���g�p���܂��B���������āA�N���C�A���g�� NTLM
��L���ɂ���K�v������܂��B
�N���X�^�\���� NIC ���n�[�h�E�F�A�ɒlj�����ƁA�������o���p�u���b�N�l�b�g���[�N�Ƃ��Ďg�p���܂��B�܂��A��x NIC ���O���ĕt���ւ����ꍇ�A�ʂ� NIC �Ƃ��čĐݒ肵�Ďg�p���܂��B
IP �̐ݒ�
���z�T�[�o�[ IP
�A�h���X�͐ÓI�ɐݒ肷��K�v������܂��BDHCP
����̐ݒ�͂ł��܂���B�e�̃m�[�h�� IP �A�h���X�� DHCP
����擾�\�ł����A�����͂��Ă��܂���B
�u���E�W���O
�e�m�[�h���A�y�уN���X�^���z�T�[�o�[���̓u���E�W���O�̑ΏۂɂȂ�܂��B�N���C�A���g�Ƀm�[�h�������J�������Ȃ��ꍇ�́A"$"
�� NetBIOS
���̍Ō�ɂ��ău���E�W���O�̍ۂɉB���悤�ɂ��܂��B
NIC �̐ݒ�
�m�[�h�� NIC
�̐ݒ�́A������g�p���鉼�z�T�[�o�[�l�b�g���[�N�ł������p���܂��B�m�[�h��
TCP/IP �̐ݒ�ŁAWINS �� DNS
���g�p����ݒ�̏ꍇ�A���z�T�[�o�[�� WINS �� DNS
���g�p���܂��B
�����ʐM
�m�[�h�Ԃł���肳���A����ʐM�ł��B��Ɉȉ��̂��Ƃ��s���Ă��܂��B
�A�v���P�[�V�����ˑ��ł����A�N���X�^���O�i�g�����U�N�V�����f�[�^�j���傫���Ȃ�悤�Ȃ�A������x�̑������̂ɂ����������肵�܂��B�ʏ�N���X�P�[�u���Ō��т܂��B
�T�u�l�b�g
�S�m�[�h�͓���̃T�u�l�b�g�ɐݒ肷��K�v������܂��B���[�^����ĕʃT�u�l�b�g�Ƀm�[�h���쐬�����ꍇ�AIP
�A�h���X���\�[�X���t�F�[���I�[�o�[���Ă����삵�Ȃ��Ȃ�܂��B
Fault Tolerant NIC
�t�H�[���g�g�������X�p NIC
�̓v���C�x�[�g�l�b�g���[�N�Ɏg�p���邱�Ƃ͐������܂���B�N���X�^�ł̓v���C�x�[�g
NIC
����Q���N�����ƒ����ɐ�ւ��܂����A���̖W���ɂȂ�����A��쓮�̌����ƂȂ�܂��B�܂��AFT
�p�̗]�v�ȃp�P�b�g�������̂ŁA�x���̌����ɂ��Ȃ�܂��B
IP Address ���\�[�X�̃t�F�[���I�[�o�[
IP Address ���t�F�[���I�[�o�[�����ꍇ�AARP Broad Cast
������܂��B����ɂ��T�u�l�b�g���̑S�}�V���� ARP
�L���b�V�����ύX����܂��B�Z�O�����g�������ꂽ�N���C�A���g�́A���[�^�̃L���b�V��������������Ă���̂Ŗ�肠��܂���Barp
-a
�R�}���h�Ŋm�F�ł���̂ŁA�t�F�[���I�[�o�[�O�������ׂ邱�Ƃ��\�ł��B
Cluster Network Driver
�N���X�^�̃l�b�g���[�N�h���C�o�� %systemroot%\system32\drivers\ClusNet.sys
�ɂ���܂��B
�@
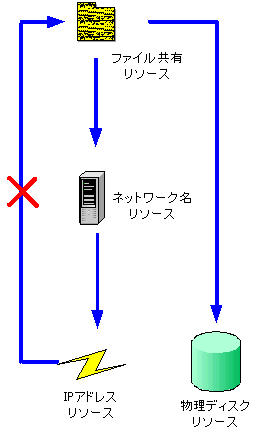
���\�[�X�Ƃ̓N���X�^�T�[�r�X�ɂ���ĊǗ������{�P�ʂł��B�����I���邢�͘_���I�ȗv�f�ł��B�������炩�̋@�\�i�����j�������Ă��܂��B��\�I�ȃ��\�[�X�Ƃ��ĉ��L�̂悤�Ȃ��̂�����܂��B
���\�[�X���ǂ���������Ԃɂ��邩�́A���\�[�X���j�^�iResource Monitor�j ���Ď����Ă��܂��B�������A���\�[�X���j�^�́A���ڃ��\�[�X���Ď����Ă���킯�ł͂Ȃ��A���\�[�X DLL�iResource DLL�j��ʂ��čs���Ă��܂��B�܂�A���\�[�X���j�^�́A�N���X�^�T�[�r�X�ƃ��\�[�X�̒�����̂悤�Ȗ������ʂ����Ă��܂��B���\�[�X DLL �̓N���X�^ API ���g�p���č쐬���ꂽ�_�C�i�~�b�N�����N���C�u�����ł��B���\�[�X�̊Ď��̓��e�i�ǂ��Ȃ����烊�\�[�X����Q�Ƃ������f�����邩�j�͂��̃��\�[�X DLL �ɂ���ĕω����܂��B���\�[�X���j�^�́A���\�[�X DLL ����̕��܂Ƃ߂āA�N���X�^�T�[�r�X�ɕ��܂��B��̃��\�[�X���j�^�́A1674 ���\�[�X�����j�^�ł��܂��B
�ėp�A�v���P�[�V������A�ėp�T�[�r�X�̓��\�[�X DLL �������܂���B��Q�̌��m�̓v���Z�X�����s����Ă��邩�����Ĕ��f���܂��B�]���āA�n���O�����ꍇ�Ȃǎ��s����Ă��邯�Ǐ�������~���Ă���ꍇ�ɂ́A��Q�Ƃ݂Ȃ��Ȃ��̂ŁA���X�^�[�g��t�F�[���I�[�o�[�͍s���܂���B
���\�[�X�̐ݒ�́A�����̃m�[�h���N�����Ă����Ԃł�����A���A���^�C���ɕύX���ʃm�[�h�֓n����܂��B�Е��̃m�[�h�������Ă���ꍇ�́Aquolog.log �ɕύX�������c���܂��B
�@
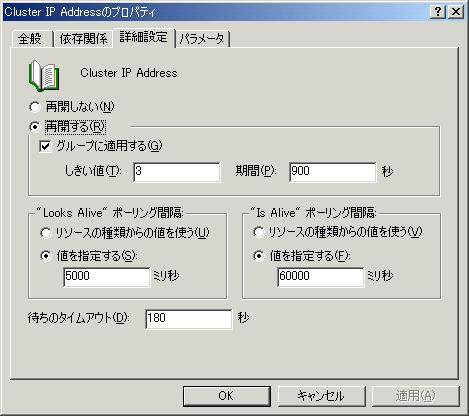
| �v���p�e�B
���\�[�X�̃v���p�e�B�ł̓p�����[�^�ȊO�̍��ڂ́A�S�Ẵ��\�[�X�œ����ł��i�ݒ�l�͈Ⴂ�܂��j�B�ڍאݒ�^�u�̒��g���ȒP�ɐ������܂��B [�ĊJ����][�ĊJ���Ȃ�] [�O���[�v�ɓK�p����] [�������l][����] [Looks Alive �|�[�����O�Ԋu] [Is Alive �|�[�����O�Ԋu] [�҂��̃^�C���A�E�g] |
 |
�@
| �ˑ��W�́A�K�v�Ƃ��郊�\�[�X�ƕK�v�Ƃ���郊�\�[�X��
2
�̃��\�[�X�̊W�ł��B�ˑ�����Ă��郊�\�[�X���I�����C���łȂ��ꍇ�A�ˑ����郊�\�[�X�̓I�����C���ɂȂ邱�Ƃ͂ł��܂���B���̊W��
Windows �̃T�[�r�X�̊W�Ɠ����ł��B�Ⴆ�AComputer
Browser �T�[�r�X�́AServer �T�[�r�X�� Workstation
�T�[�r�X���N�����ĂȂ��ƋN�������Ƃ��ł��܂���B����Ɠ����悤�ɁA�l�b�g���[�N�����\�[�X��
IP �A�h���X���\�[�X�Ɉˑ����Ă���̂ŁAIP
�A�h���X���\�[�X���I�����C���ɂȂ�Ȃ�����A�l�b�g���[�N�����\�[�X���I�����C���ɂȂ邱�Ƃ͂ł��܂���B
�ˑ��W�ɂ͈ȉ��̃��[��������܂��B
|
�P������݂̂̈ˑ��W�̂݉\ |
�@
�t�F�[���I�[�o�[�Ƃ́A��Q�������ɁA���\�[�X������m�[�h����ʂ̃m�[�h�Ɉړ����鏈���̂��Ƃł��B
���\�[�X����Q���N�����ƁA�܂��́A���̃m�[�h���Ń��\�[�X�̃��X�^�[�g�iReStart�j�������s���܂��B�ݒ肵�����ԓ��ŁA�ݒ肵�����X�^�[�g�Ɏ��s�����ꍇ�A�t�F�[���I�[�o�[�������s���܂��B
���\�[�X�����������ď�Q�Ƃ݂Ȃ����́A���\�[�X DLL �ɂɂ��̂ŁA���\�[�X�ɂ���ĈႢ�܂��B�Ⴆ�� SQL �̃��\�[�X�� SQL Query �ɒǂ��Ƃ��邩�Ŕ��f���Ă��܂��B
�t�F�[���I�[�o�[���̓N���C�A���g�Ƃ̐ڑ��͐ؒf����܂��B�ؒf����Ă��鎞�Ԃ́A�T�[�r�X���J�n�����܂ł̎��ԂȂ̂ŁA�o�^����Ă��郊�\�[�X�ɂ���ĈقȂ�܂��B�N���C�A���g�A�v���P�[�V�����́A�����I�ɍĐڑ�����悤�ɊJ�����邩�A�^�p�ōĐڑ����s�킹��Ȃǂ̑Ώ����K�v�ɂȂ�܂��BIIS �Ȃǂ� Web Server �� ReLoad ���s���悢�̂ŁA���[�U�[�ɋC�t����ɂ����ł��B
�t�F�[���I�[�o�[���ɂ́A�ȉ��̂��Ƃ���������̂ŁA���̂��Ƃ��l�����ĉ^�p���l����K�v������܂��B
�@
�t�F�[���o�b�N�Ƃ́A��Q���N�����t�F�[���I�[�o�[�������\�[�X���A��Q���A����Ƃ̃m�[�h�ɖ߂鏈���̂��Ƃł��B�f�t�H���g�ł̓t�F�[���o�b�N�̐ݒ�͖����ɂȂ��Ă��܂��B�t�F�[���o�b�N�𗘗p�������ꍇ�́A�D�揊�L�҂����߂āA���t�F�[���o�b�N���s�������w�肵�܂��B���Ԃ̎w����@�́A���A�㒼���ɍs�����A�������̎��ԑтɂȂ�����i�[��Ȃǁj�s���Ƃ��� 2 ��ނ̐ݒ���@������܂��B�t�F�[���o�b�N�̐ݒ�̓O���[�v���Ƃɍs���܂��B
�@
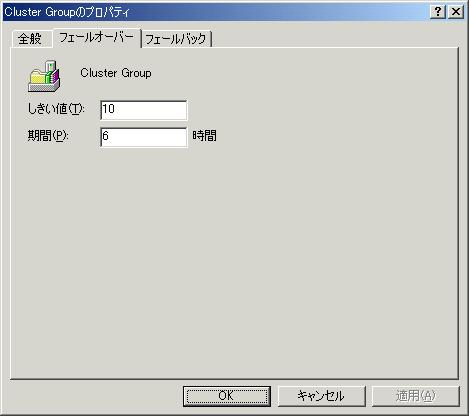
| �O���[�v�̃v���p�e�B
�O���[�v�̃v���p�e�B�ŁA�t�F�[���I�[�o�[�ƃt�F�[���o�b�N�̐ݒ���s���܂��B �t�F�[���I�[�o�[�̐ݒ�� [�t�F�[���I�[�o�[] �^�u�ōs���܂��B[�������l] �� [ ����] �́A���̃O���[�v����Q�ɂȂ�܂ł̎��ԊԊu�ł��B�E�}�ł́A6 ���Ԉȓ��� 10 ��t�F�[���I�[�o�[���s��ꂽ��A��Q�Ƃ��ĔF������܂��B �t�F�[���o�b�N�̐ݒ�́A�܂��A[�S��] �^�u�ŁA[�D�揊�L��] �����߂܂��B���ɁA[�t�F�[���o�b�N] �^�u�ŁA[�t�F�[���o�b�N��������] �Ƀ`�F�b�N�����܂��B[������] ��I������ƁA�D�揊�L�҂Őݒ肵���m�[�h���N��������A�����Ƀt�F�[���o�b�N���s���܂��B[���̎��ԑ�] �Ńt�F�[���o�b�N�������鎞�ԑт��w��ł��܂��B���̎��ԑтɗD�揊�L�҂Ƀm�[�h�ŃO���[�v�����s����Ă��Ȃ�������A�t�F�[���o�b�N�������s���܂��B�f�t�H���g�ł� [�t�F�[���o�b�N���֎~����] �Ƀ`�F�b�N�������Ă��܂��B �t�F�[���I�[�o�[�̂������l�̃J�E���^�����ɖ߂��ɂ́ACluster Service ���ċN�������邵�����@�͂���܂���B |
|
�@
SCSI
���L�f�B�X�N��I������ꍇ�ɂ� SCSI
�̋K�i���悭�������đI�����܂��B�ڂ����͐�发�Ȃǂ��Q�Ƃ��Ă��������B�����ł́A�ȒP�ɗp��ƃ|�C���g�Ȃǂ����Љ�܂��B
| �K�i | pin | bit | Max Transfer (MB/s) | Internal Transfer Rate (MB/s) |
| SCSI and SCSI�U | 50 | 8 | 10 | 4 �` 8 |
| Wide SCSI | 68 | 16 | 20 | 7 �` 15.5 |
| Ultra SCSI | 50 | 8 | 20 | 7 �` 15.5 |
| Ultra Wide | 68 | 16 | 40 | 7 �` 30 |
�@
| �`�F�b�N�|�C���g | ���� |
| Bas Speed | �f�o�C�X�C���^�[�t�F�[�X�ƃJ�[�h�C���^�[�t�F�[�X�Ԃ� SCSI �P�[�u����̃f�[�^�]�����x�BBas Speed ���x���ƃf�B�X�N�̑��x�����Ȃ��ꍇ������B |
| Internal Transfer Rate | �n�[�h�f�B�X�N�̓����]�����x�B |
| Max Bus Length *1 | �o�X�̏I�[����I�[�܂ł̒����B |
* 1 ���� SCSI �Ŏg�p����Ă���C���^�[�t�F�[�X�M���`��
1. SE�iSingle ended�j
���ʂ� SCSI �C���^�[�t�F�[�X�M���`���B�m�C�Y�̉e�����₷���A�K�i������������x�ɍő咷���Z���Ȃ�B
2. HVD�iHigh Volume Differential�j
�σm�C�Y������B�o�X�ő咷 25 ���[�g���܂ʼn\�B���{�ł͗]��g���Ȃ������M�������B
3. LVD�iLow Volume Differential�j
�σm�C�Y���v���X�]�����x������B
| �^�[�~�l�[�^�iTerminator�j | ���� |
| Passive Termed | SCSI�T�̍�����W���Ŏg�p����Ă���B�ł��V���v���Ȍ`���B |
| Active Temed | SCSI�U�̕W���B�d�������@�\�t�B |
| FPT | Force Perfect Termination�BActive �^�C�v����i���������́B�g�`��@�\�t�B |
| �^�[�~�l�[�^�� 4.5v
�ȏ�d�����Ȃ��Ƌ@�\���Ȃ����Ƃ�����܂��B�^�[�~�l�[�^�p�̓d�����m�ۂł���Ƃ����S�ł��B �N���X�^�̏ꍇ�A�I���{�[�h�^�[�~�l�[�^���g�p���邩�AY�P�[�u�����g�p�����ق����悢�ł��傤�B�I���{�[�h�̏ꍇ�A�d�C���ʂ��ĂȂ��Ɠ��삵�Ȃ����̂�����̂ŁA�S�m�[�h���N�����Ă����ABoot.ini �̉�ʂŕЕ����~�߂Ă����Ȃǂ̑Ώ����K�v�ȏꍇ������܂��B |
|
| SCSI BIOS �ݒ� | ���� |
| SCSI ID �̏d�� | SCSI �J�[�h�̃f�t�H���g ID �� 7 �ɐݒ肳��Ă��邱�Ƃ������B�N���X�^�\���̏ꍇ�A2���̃J�[�h����̃o�X��ɂ���̂ŁAID ���d������B��ʓI�Ɉꖇ�� ID6 �ɕύX����B |
| Bus Reset �̖��� | SCSI �̋@�\�Ńf�B�X�N�� Ownership ��s���ɂȂ�\��������̂ŁA�\�� Disabled �ɐݒ肵�Ă����������悢�B |
�@
�t�@�C�o�[�`���l���iFibre Channel�j
�t�@�C�o�[�`���l����ANSI
X3T11�iSCSI3)�ŋK�肳��Ă��܂��B�ȉ��ɓ����������܂��B
�@
�M����
���L�f�B�X�N�́A�����C����A�ȒP�� CHKDSK
���s���Ȃ��̂ŁASTOP
�Ȃǂŗ������Ƃ��Ɉ��S���̊m�ۂ��ł��܂���B���L�f�B�X�N��
SCSI ���g�p�����ꍇ Software RAID �͎g�p�ł��܂���BHardware
RAID �͍\���\�Ȃ̂ŁA�f�[�^����邽�߂ɂ� Hardware RAID
���g�p���܂��B�������A�e�m�[�h�̃��[�J���f�B�X�N��
Software RAID ���g�p�ł��܂��B
�h���C�u���^�[
���L�f�B�X�N�̃h���C�u���^�[�́A�Ō�̕�����t���������悢�ł��BCD-R
�Ȃǂ̒lj��ɂ��A���̕��̃h���C�u���^�[�������A���L�f�B�X�N�̃h���C�u���^�[������Ă��܂��\��������܂��B�h���C�u���^�[���ς��ƃN���X�^�͓��삵�Ȃ��Ȃ��Ă��܂��܂��B
Cluster Disk Driver
�N���X�^�̃f�B�X�N�h���C�o�́A%systemroot%\system32\driveres\ClusDisk.sys
�ɂ���܂��B
Challenge/Define Protocol
�N���X�^�T�[�r�X�ł́A��̃f�B�X�N�����̃m�[�h����L���܂��B���̎��̐���A���S���Y����
Challenge/Define Protocol
�Ƃ����܂��B�m�[�h���f�B�X�N�����L����ƃZ�}�t�H��
"lease"
�Ə������݂܂��B�Z�}�t�H�Ƃ́A�����̃v���O��������������ۂɗ��p����t���O�̂悤�Ȃ��̂ł��B�����f�B�X�N���L�҂������A�f�B�X�N�ɃA�N�Z�X����K�v���Ȃ��Ȃ�A�Z�}�t�H���N���A���āA���̃R���s���[�^��
Reserve �ł���悤�� Release
�R�}���h���o���܂��B���L�҂���Q���N�����Ă���ꍇ�ɂ́A���̃m�[�h�����L�҂ɂȂ邽�߂ɁA�Z�}�t�H���N���A����
10 �b�҂��܂��B10 �b�Ƃ́ARenewal �v���� 3 �b�ASCSI
�o�X�����肷��܂ł� 2 �b�A����� 2 ��s�������l�ł��B10
�b�����Ă��A���L�҂����Ȃ��悤�Ȃ�A���̃m�[�h�� Reserve
�R�}���h���g�p���A�f�B�X�N���擾���܂��B
�@
�N���X�^�̓����ł͈ȉ��̃R���|�[�l���g���A���ꂼ��������������삵�Ă��܂��B
Event Processor
�C�x���g�v���Z�b�T�́A�N���X�^�T�[�r�X�ŒʐM�̒��j�ƂȂ�R���|�[�l���g�ł��B�A�v���P�[�V�����ƁA�N���X�^�T�[�r�X�̂ق��̃R���|�[�l���g�����ѕt���܂��B�܂��A�N���X�^�T�[�r�X�̋N����A�m�[�h�̃I�t���C����Ԃɂ���������ʂ����܂��B�N���X�^�̌`����A�Q���Ȃǂ̏������J�n���邽�߂�
Node Manager
���Ăяo������������܂��B���̑��A���L�̋@�\��L���܂��B
Node Manager
�m�[�h�}�l�[�W���́A���̃m�[�h�̃G���[���o���s���܂��B��̓I�ɂ̓n�[�g�r�[�g�̂������s���܂��B�ʃm�[�h����~���Ɣ��f�����ꍇ�ɂ́A�n�[�h�r�[�g�̑��M���~�߂܂��B�n�[�g�r�[�g���r�ꂽ��
Failover Manager �� Membership Manager �ɕ����܂��B
���炩�̌����ŁA�m�[�h�ԒʐM�̂ݕ��ʂɂȂ�A�e�m�[�h�͐���ɓ��삵�Ă���Ƃ��܂��B���̏ꍇ�A���݂��̃m�[�h�ő���̃��\�[�X�������̃m�[�h�ŃI�����C���ɂ��悤�Ǝ��݂܂��B�������A����ł͗����ŃI�����C���Ɏg�p�Ɠ��삵�A�����������Ȃ��Ȃ�̂ŁA�N�H�[�������\�[�X�𐧌䂵�Ă���m�[�h�őS�Ẵ��\�[�X���I�����C���ɂ��܂��B
Membership Manager
�����o�[�V�b�v�}�l�[�W���́A�ǂ̃����o�[���N���X�^�Ƃ��ē��삵�Ă��邩��c�����܂��B��Ɉȉ��̏������s���܂��B���̂Ƃ��̒ʐM�̓��j�L���X�g�ōs���܂��B
Global Update Manager
�O���[�o���A�b�v�f�[�g�}�l�[�W���́A�ύX����ʂ̃m�[�h�Ƀ}�b�v�i�����j���s���܂��B�܂��A���\�[�X�̏�Ԃ̕ω����A�N���X�^���̃m�[�h�ɗp�ӂɒʒm�ł���d�g�݂���܂��B
Database Manager
�f�[�^�x�[�X�}�l�[�W���́A�N���X�^�f�[�^�x�[�X�̊Ǘ����s���܂��BGUM
����ʒm��������ALocal DB
�ɏ��f�����܂��B���̃m�[�h�̃f�[�^�x�[�X�Ɩ����������Ȃ��悤�ɁA���݂��ɋ������Ă��܂��B
Log Manager
���O�}�l�[�W���͂����ꂩ�̃m�[�h�����삵�Ă��Ȃ��Ƃ��́Aquolog.log
�֍\���ύX�����������݂��s���܂��B�܂��A�`�F�b�N�|�C���g�t�@�C���ichk***.tmp�j�ȂǂƂ��������Ă��܂��B
Resource Manager/Failover Manager
���\�[�X�}�l�[�W���̓��\�[�X�����j�^�����X�^�[�g�������s���悤�Ɏ�z���܂��B���X�^�[�g�Ɏ��s���A��Q�ƌ��m������A�t�F�[���I�[�o�[�}�l�[�W���ɗv�����o���܂��B���̌�A�t�F�[���I�[�o�[�}�l�[�W�����������s���܂��B
Pushing a group
���u�[�g�ȂǂŃm�[�h����T�[�r�X���~����Ƃ��́A��~���邱�Ƃ𑼂̃m�[�h�ɒʒm����B�������牟���o���̂�
Push �ɂȂ�܂��B
Pulling a group
�n�[�h�r�[�g�� 6 �s����Ə�Q�ɂȂ�ARegroup
�������J�n����A���̃m�[�h�̃��\�[�X���������݂܂��B���肩���������̂�
Pull �ɂȂ�܂��B
Communication Manager
�R�~���j�P�[�V�����}�l�[�W���͑��̃m�[�h�̃R�~���j�P�[�V�����}�l�[�W���ƒʐM����R���|�[�l���g�ł��BMembership
Manager
�����Q�ʒm����ƁA���̃m�[�h�Ƃ͂��������Ȃ��Ƃ���������s���Ă��܂��B�����ʐM��
RPC ���g�p���܂��B
�N���X�^�Ŏg�p�ł��� API �͑傫�� 3 ��ނɕ������A���ꂼ��ɗp�r������܂��B
Cluster API
�N���X�^�Ǘ��p�� API �ł��B
Resource API
���\�[�X�Ǘ����s�����߂̃C���^�[�t�F�[�X�����
API �ł��B
Cluster Administrator Extension API
�N���X�^�A�h�~�j�X�g���[�^��ŁA�J�X�^�����\�[�X DLL
���Ǘ��ł���悤�ɂ���C���^�[�t�F�[�X�ł��B
Extension DLL �����W�X�g���ɓo�^����ꍇ�ɂ́A���L�̃R�}���h�ʼn\�ł��B
RegClAdm [/Ccvluster] [drive:] [path] <Extension DLL>
* ���X����̂ŁA�������킩��ɂ������Ǝv���܂��B�\�������܂���B
�@